")

Situation
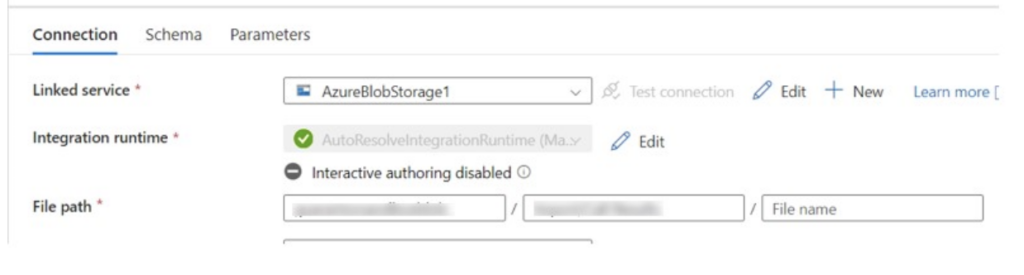
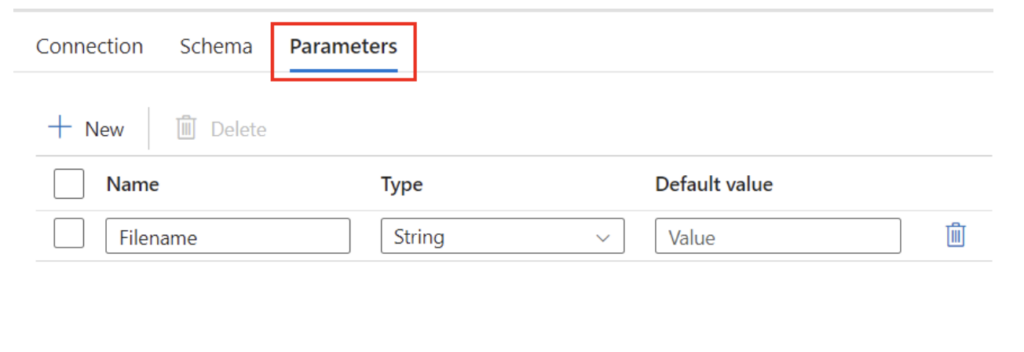
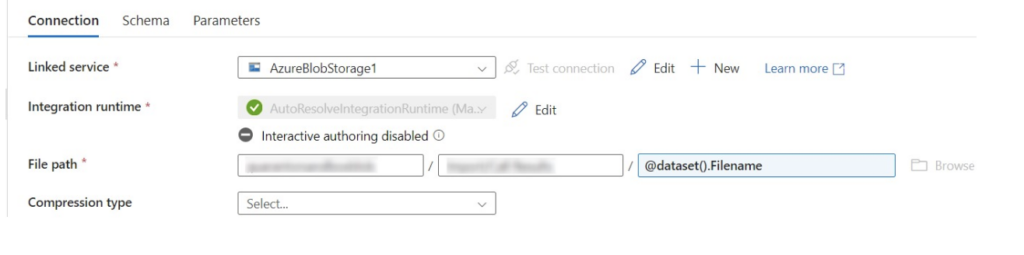
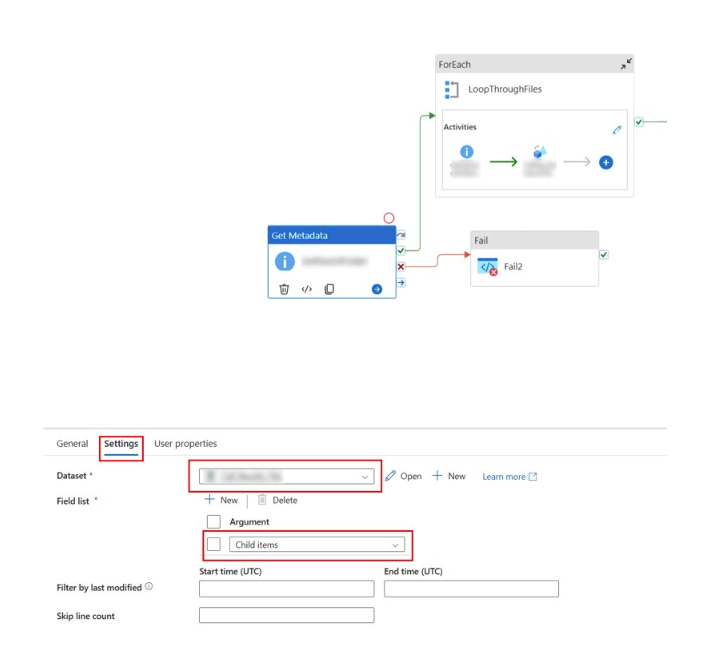
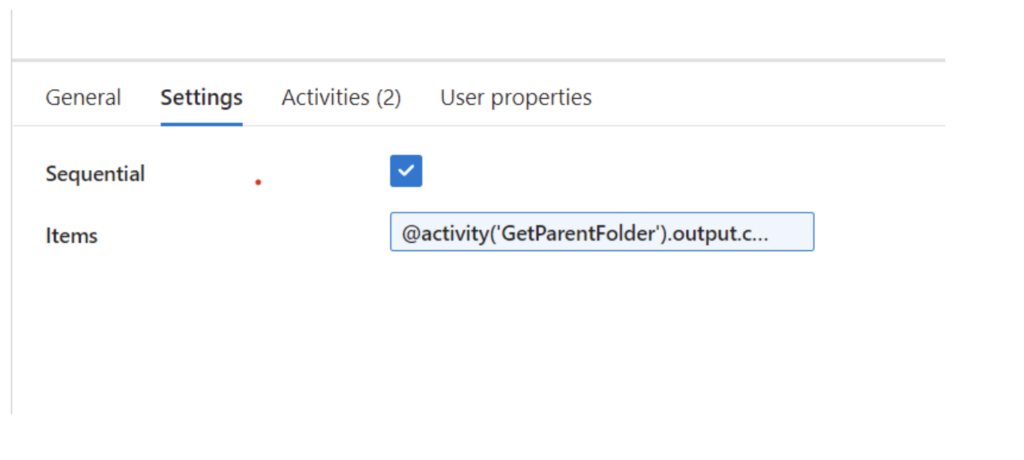
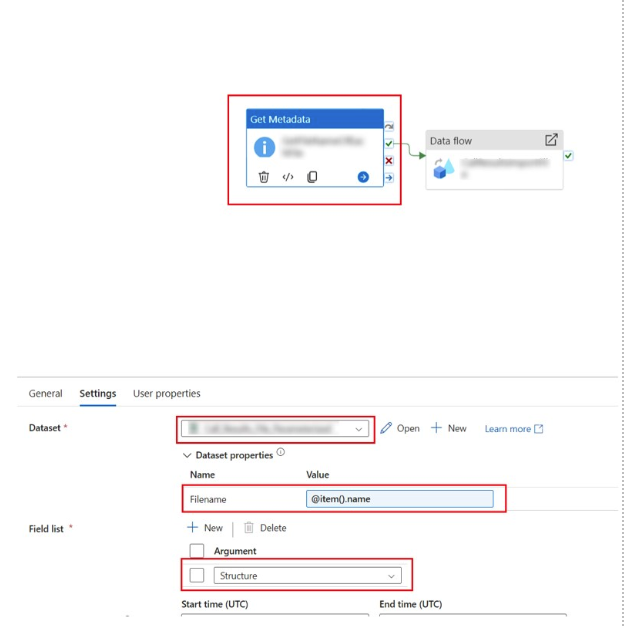
I decided to write this blog post after encountering multiple situations where there was a need to extract, transform and load multiple files from a folder as a Source into Dynamics 365. In one particular case, our client had multiple flat files that were dropped into a blob storage daily that needed to be transformed sequentially and loaded into their Dynamics environment.